吴锴的博客Life? Don't talk to me about life!2023-10-20T09:48:31.698Zhttp://www.wukai.me/noironHexo如何使用 Service Worker 来缓存图片http://www.wukai.me/2023/10/20/service-worker-cache/2023-10-19T16:00:00.000Z2023-10-20T09:48:31.698Z大家应该都听过 service worker 这个概念,那么它究竟是什么呢?我们看下MDN上的解释:
Service workers essentially act as proxy servers that sit between webapplications, the browser, and the network (when available). They areintended, among other things, to enable the creation of effectiveoffline experiences, intercept network requests and take appropriateaction based on whether the network is available, and update assetsresiding on the server. They will also allow access to pushnotifications and background sync APIs.
Service worker 在 web应用、浏览器和网络之间扮演代理服务器的角色。可以用于创建有效的离线体验,劫持网络请求等。
在这篇文章中我创建了一个示例项目来展示 service worker的基本用法及如何缓存图片。可以在这个项目service-worker-demo 中看到文中的代码。
Service Worker 使用基础
首先使用 Vite 来创建一个新项目,运行 yarn create vite后选择 vanilla 即可。
在 public 目录下创建一个名为 sw.js 的service worker 文件:
1 2
// sw.js console.log('This message is from service worker file.');
开启开发模式 yarn dev 后,可以在类似http://localhost:5173/sw.js 的位置看到这个文件。
Service woker 在生效前要经历注册(register)的过程,在main.js 文件中加入以下代码来注册 service worker:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
if ('serviceWorker'in navigator) { window.addEventListener('load', function () { navigator.serviceWorker.register('/sw.js').then( function (registration) { // Registration was successful console.log('ServiceWorker registration successful'); }, function (err) { // Registration failed console.log('ServiceWorker registration failed: ', err); } ); }); }
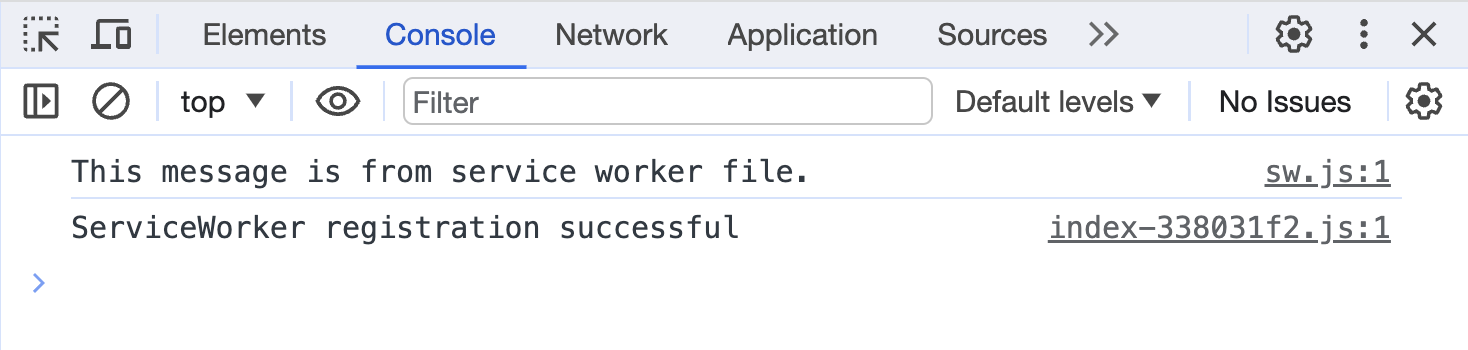
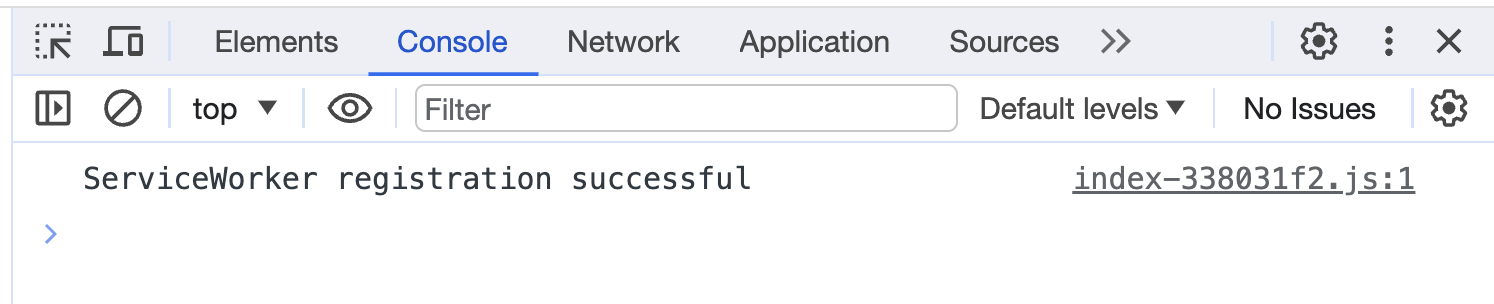
启动项目并打开页面,会在控制台看到以下内容:
控制台输出
第一条输出来自 sw.js 文件,表明这个 service worker已经运行。第二条输出来自 main.js 文件中对 service worker注册的过程,表明成功注册了。
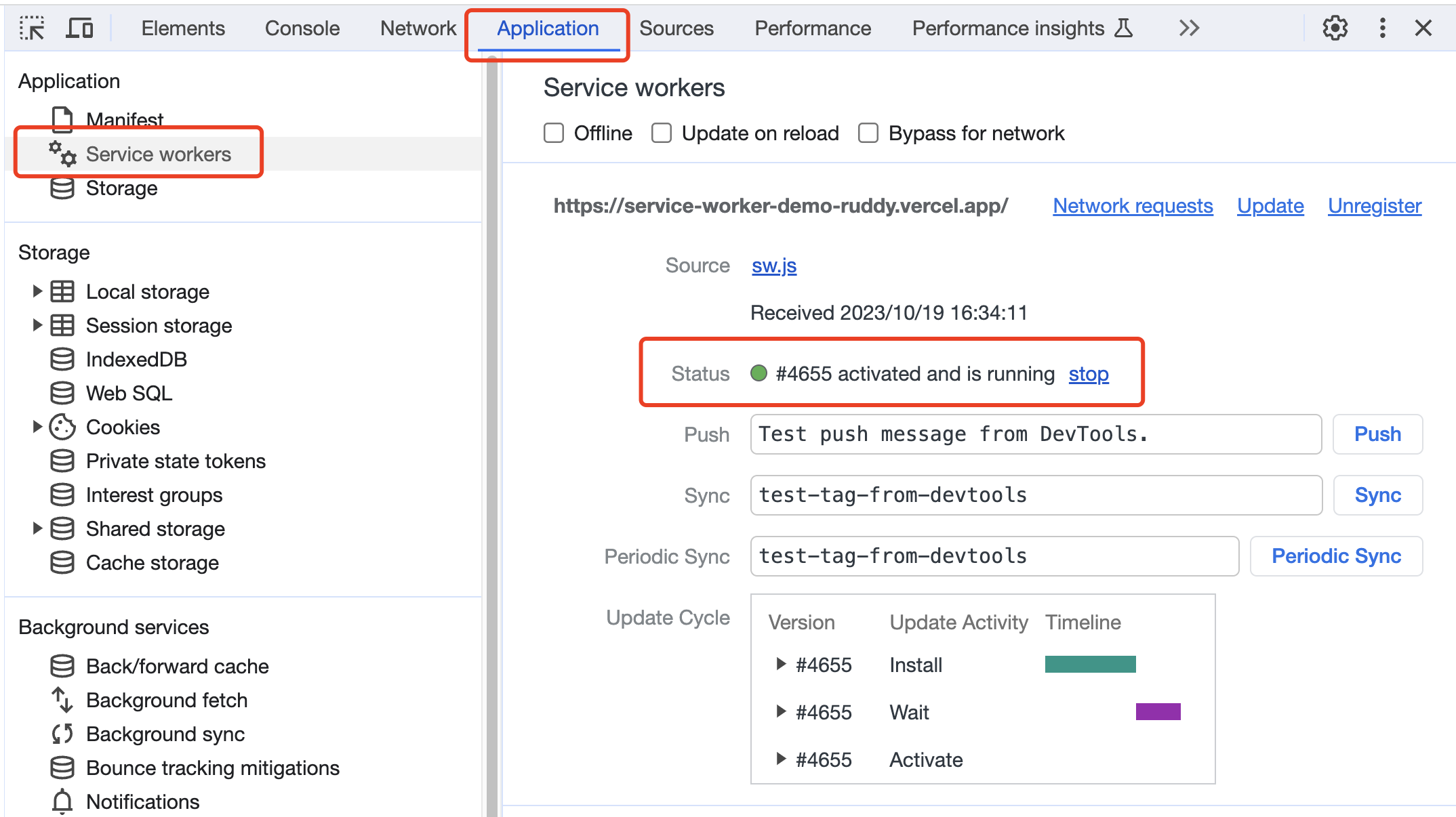
打开 Application 标签页可以看到 service worker 状态是activated and is running:
service worker 状态
如果这时候刷新页面,会发现控制台中少了一条输出:
控制台输出
因为现在是已注册的状态了,所以这个文件不会再次运行。
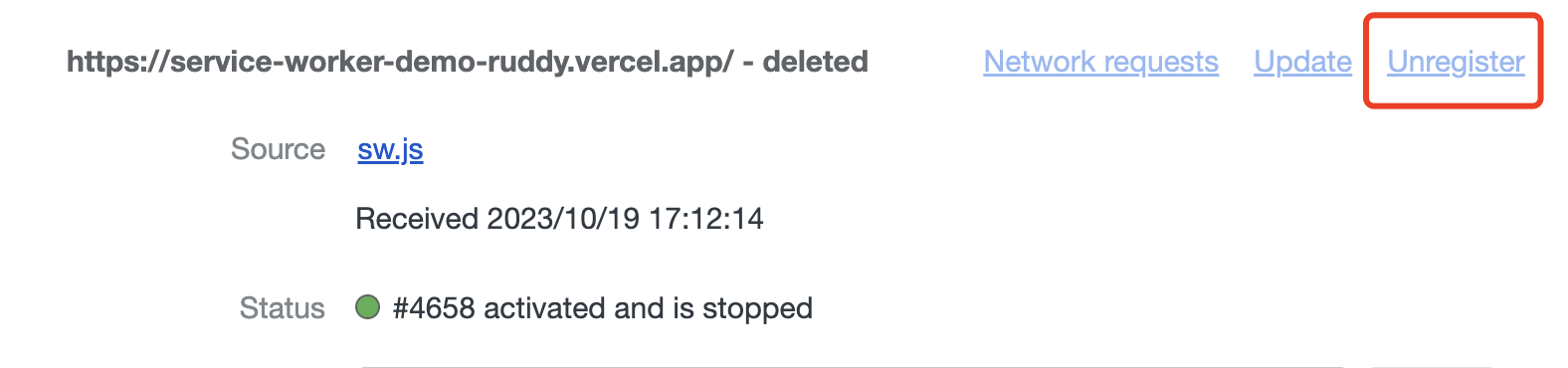
如果你点击 Unregister 按钮,则会取消这个 service worker文件的注册。之后刷新页面就会重新经历注册流程。
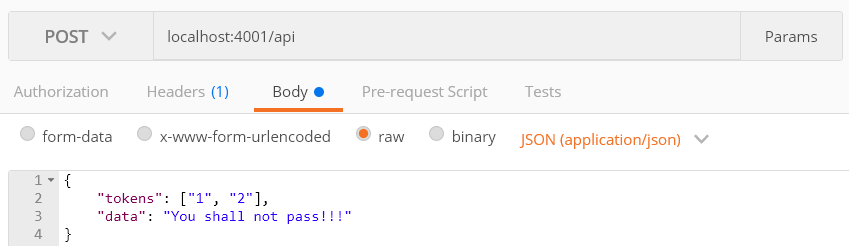
self.addEventListener('fetch', async (event) => { if (event.request.destination === 'image') { // Open the cache event.respondWith( caches.open(cacheName).then((cache) => { // Respond with the image from the cache or from the network return cache.match(event.request).then((cachedResponse) => { return ( cachedResponse || fetch(event.request.url).then((fetchedResponse) => { // Add the network response to the cache for future visits. // Note: we need to make a copy of the response to save it in // the cache and use the original as the request response. cache.put(event.request, fetchedResponse.clone());
return fetchedResponse; }) ); }); }) ); } });
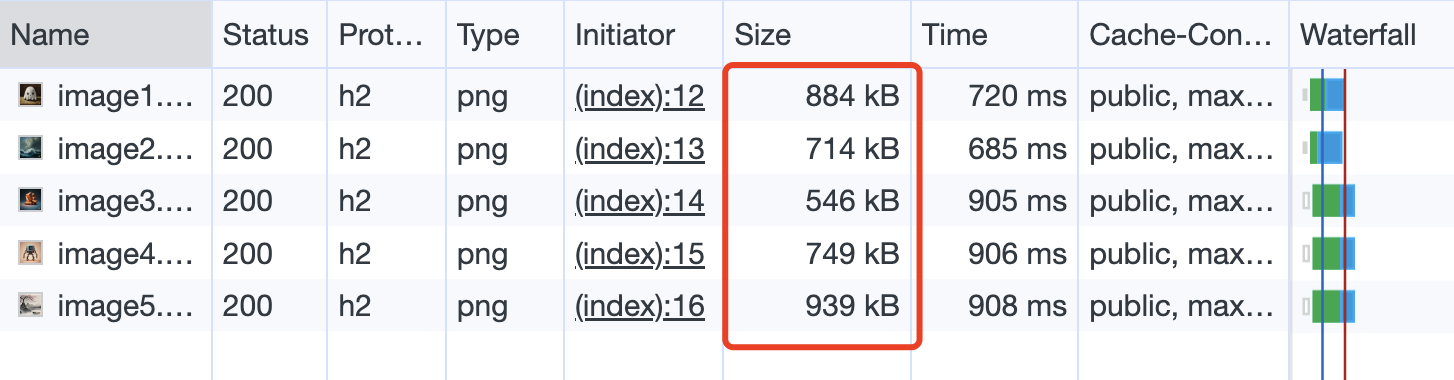
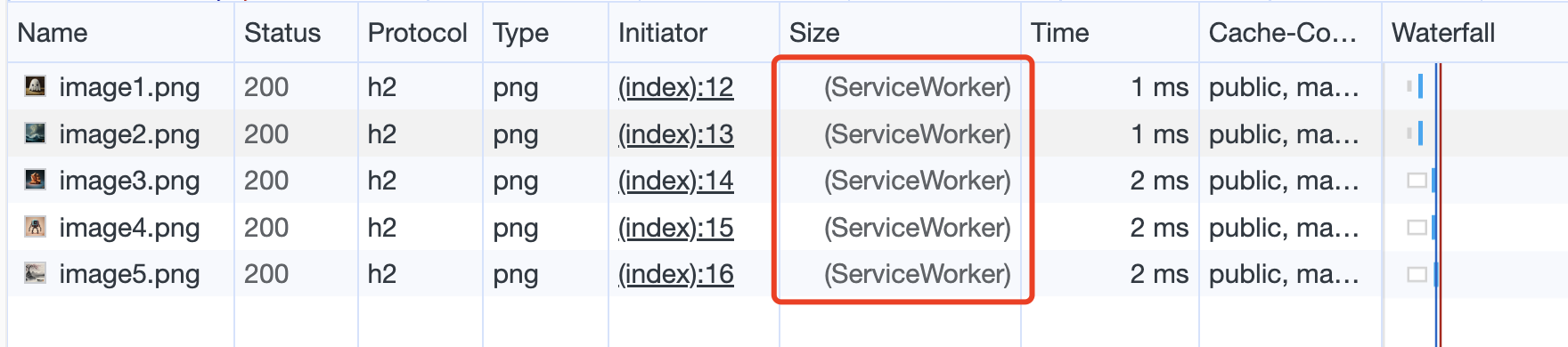
看一下这段代码的效果,为了能让更新后的 service worker文件生效,需要重新打开页面。现在 Size 栏展示的是(ServiceWorker),表示图片已由 service worker进行了缓存。
Network 请求状态
接下来解释下这段代码做了什么。
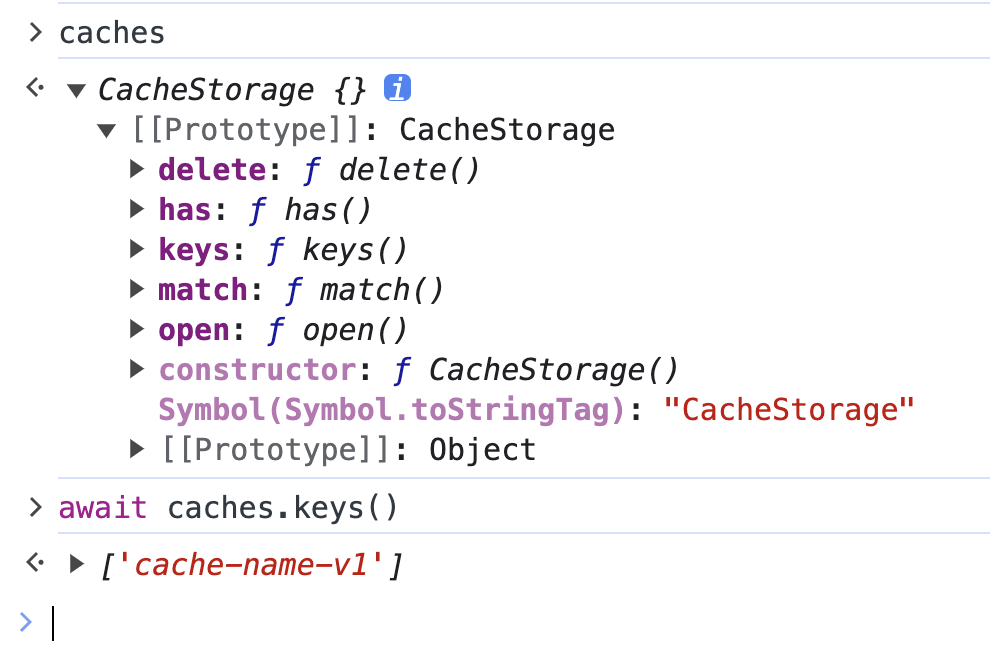
我们一直在说 service worker可以用来缓存图片,这个缓存是放在哪里呢?这就先需要了解 CacheAPI,Cache 接口提供了对 Request / Respone对象的持久化存储机制。你也可以在 service worker以外来使用它,打开控制台:
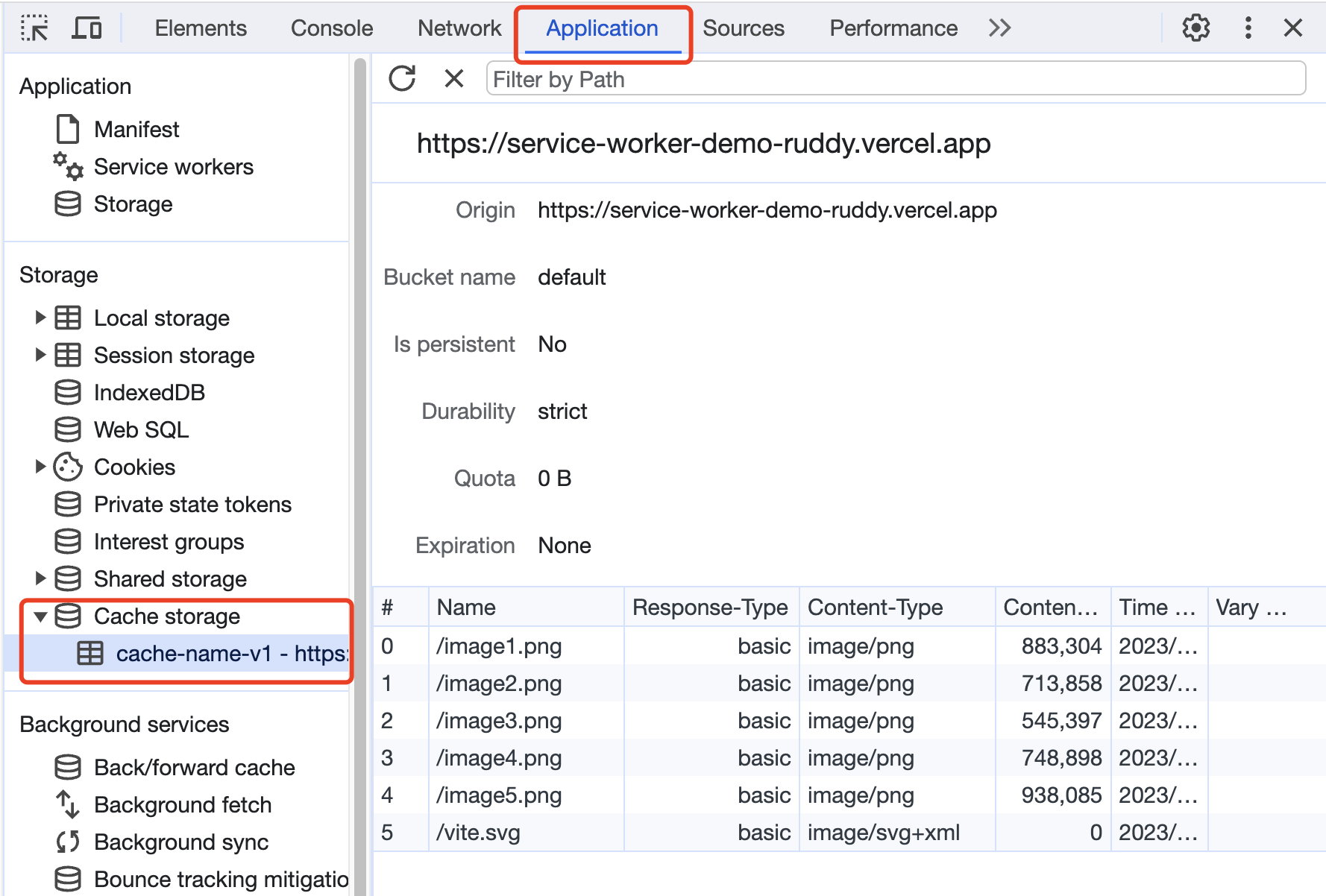
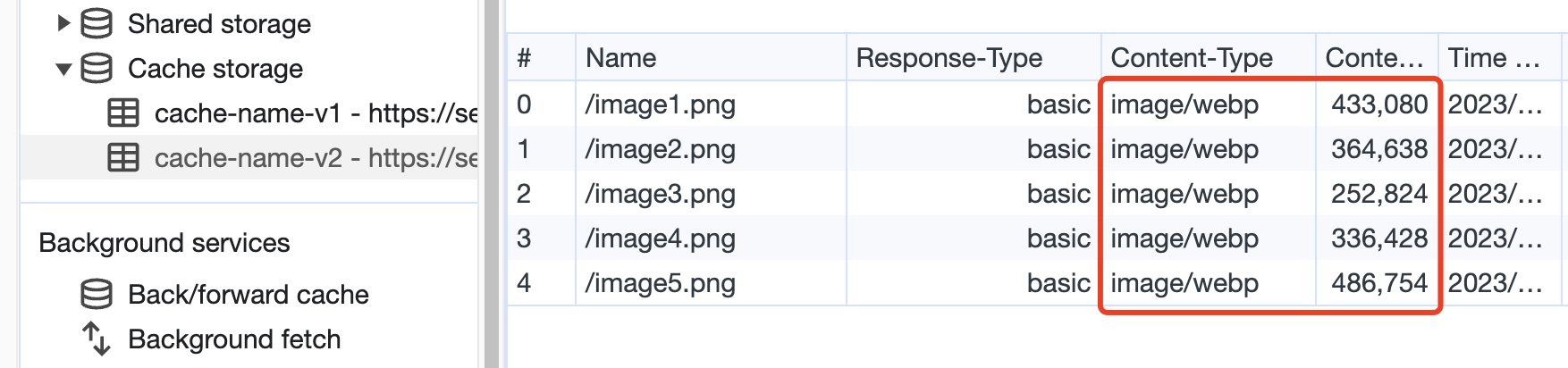
上面看到在 Network 中查看图片请求都显示来自 service worker,可以从Application -> Cache Storage 里查看具体的缓存内容。
Cache Storage
为什么要用 service worker缓存
你可能会问用 service worker 缓存有什么好处?浏览器中不是已经有了memory cache 和 disk cache 了吗?
一个使用场景是离线化应用,尝试对 sw.js文件做一点小改动,注释掉这个对类型的判断:
1 2 3
if (event.request.destination === 'image') { }
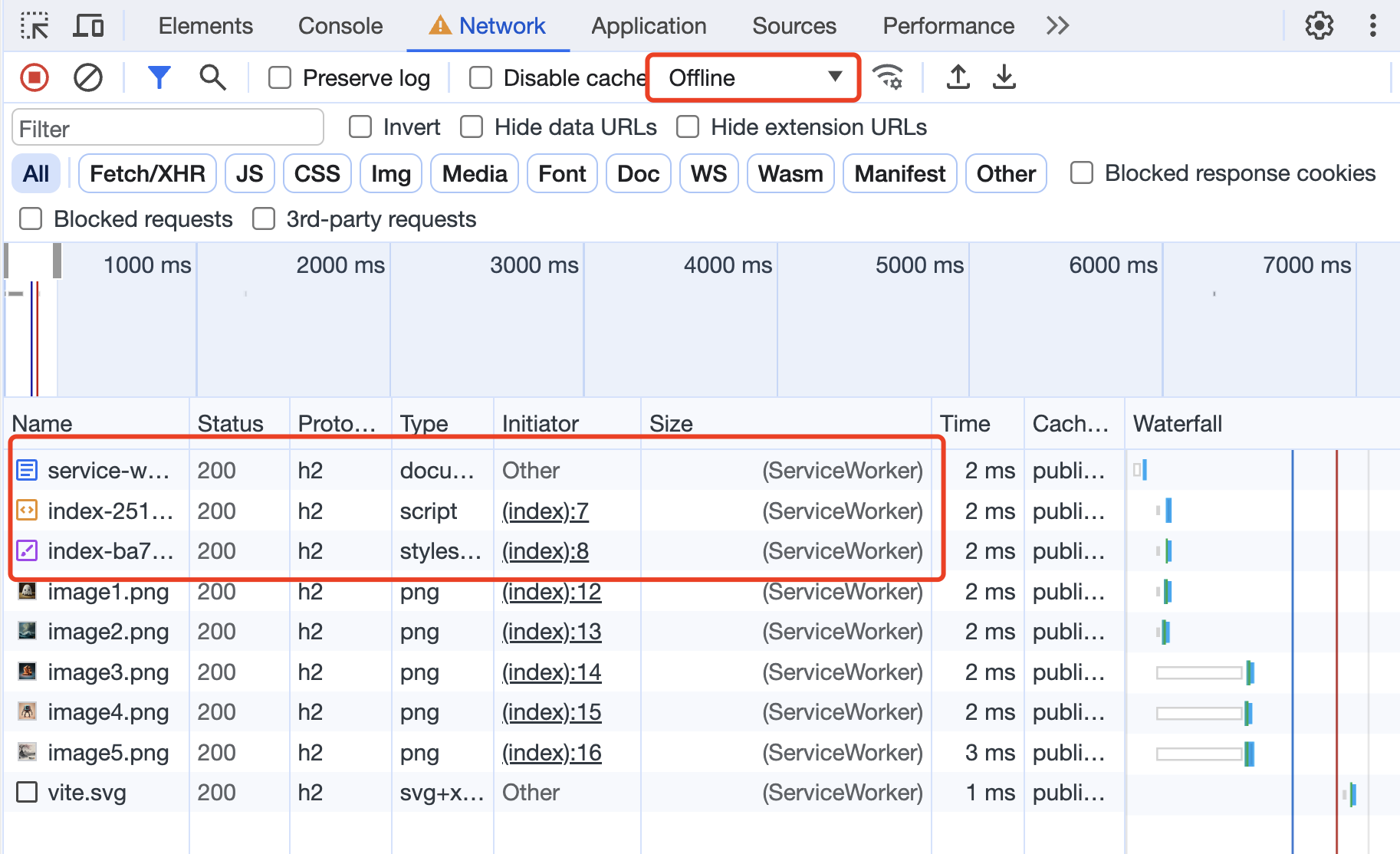
重新打开这个页面后会发现所有的资源都会走 service worker了,这时即使你断开网络也是可以正常展示的。
离线状态
利用 service worker也可以允许开发人员更精细地控制哪些资源被缓存,以及在何时更新缓存。
另一些优化
既然我们利用 service worker可以劫持所有图片的请求,那么还可以做些其他的优化,比如将图片修改为更加合适的格式。我们知道webp 是一种比 png更新的图片格式,一般会有更小的体积。某些图片服务可能提供这样的功能,在这样的url上(http://www.example.com/1.png)添加一个后缀就(`http://www.example.com/1.png?format=webp)得到了对应格式的图片。
关于 service worker 还有一点需要了解,因为 service worker可以任意修改网络请求,所以处于安全原因需要在 HTTPS 环境中才能启用。
参考资料
UsingService Workers
HowJavaScript works: Service Workers, their lifecycle and usecases
Strategiesfor service worker caching
]]>
<p>大家应该都听过 service worker 这个概念,那么它究竟是什么呢?我们看下
<a
href="https://developer.mozilla.org/en-US/docs/Web/API/Service_Worker_API">MDN</a>
上的解释:</p>
<blockquote>
<p>Service workers essentially act as proxy servers that sit between web
applications, the browser, and the network (when available). They are
intended, among other things, to enable the creation of effective
offline experiences, intercept network requests and take appropriate
action based on whether the network is available, and update assets
residing on the server. They will also allow access to push
notifications and background sync APIs.</p>
</blockquote>
<p>Service worker 在 web
应用、浏览器和网络之间扮演代理服务器的角色。可以用于创建有效的离线体验,劫持网络请求等。</p>
<p>在这篇文章中我创建了一个示例项目来展示 service worker
的基本用法及如何缓存图片。可以在<a
href="https://github.com/noiron/service-worker-demo">这个项目
service-worker-demo</a> 中看到文中的代码。</p>
《深入理解计算机系统 CSAPP》Data Lab 记录http://www.wukai.me/2023/05/16/csapp-datalab/2023-05-15T16:00:00.000Z2023-05-16T08:22:26.868Z《深入理解计算机系统CSAPP》这本书我已经买了很多年了,一直都只是翻翻而已,阅读进度常年在前两章。趁着最近有时间,再次拿出了这本书,准备好好学习一下。配套的几个lab 也试着做一下,这篇文章就是记录一下第一个 data lab 的过程。
/* * conditional - same as x ? y : z * Example: conditional(2,4,5) = 4 * Legal ops: ! ~ & ^ | + << >> * Max ops: 16 * Rating: 3 */ intconditional(int x, int y, int z){ int mask= ~!x+1; return (y & ~mask) | (z & mask); }
说明:
返回的结果是 y 和 z 中的一个,表达式应该是这样的形式(y op expr) | (z op expr)
我们需要这样的一个掩码值(表格中以16位为例):
x
mask
y & ~mask
z & mask
0
0xffff
0x0000
z
非0
0x0000
y
0x0000
这个掩码值可以通过表达式 ~!x + 1 根据 x的不同情况来求出:
x
!x
~!x
~!x + 1
0
0x0001
0xfffe
0xffff
非0
0x0000
0xffff
0x0000
isLessOrEqual
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
/* * isLessOrEqual - if x <= y then return 1, else return 0 * Example: isLessOrEqual(4,5) = 1. * Legal ops: ! ~ & ^ | + << >> * Max ops: 24 * Rating: 3 */ intisLessOrEqual(int x, int y){ int diff = ~x + 1 + y; int signD = diff >> 31 & 0x1; int signX = x >> 31 & 0x1; int signY = y >> 31 & 0x1; int sameSign = !(signX ^ signY); return (sameSign && !signD) | (!sameSign & signX); }
/* * floatFloat2Int - Return bit-level equivalent of expression (int) f * for floating point argument f. * Argument is passed as unsigned int, but * it is to be interpreted as the bit-level representation of a * single-precision floating point value. * Anything out of range (including NaN and infinity) should return * 0x80000000u. * Legal ops: Any integer/unsigned operations incl. ||, &&. also if, while * Max ops: 30 * Rating: 4 */ intfloatFloat2Int(unsigned uf){ int sign = uf >> 31; intexp = uf >> 23 & 0xFF; int frac = uf & 0x7FFFFF; int E = exp - 127;
if (exp == 255 || E > 30) { return0x80000000u; } if (!exp || E < 0) { return0; }
int result = 1 << E; // 在小数的开头加上一个1 if (E < 23) { result |= frac >> (23 - E); // 舍去小数点右侧的数字 } else { result |= frac << (E - 23); // 在小数右侧补零 }
if (sign) { result = ~result + 1; }
return result; }
说明:
根据浮点数的表示依次处理符号位、指数部分、小数部分即可。
具体说明可以参考这一篇:Converting float to intin C
floatPower2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
/* * floatPower2 - Return bit-level equivalent of the expression 2.0^x * (2.0 raised to the power x) for any 32-bit integer x. * * The unsigned value that is returned should have the identical bit * representation as the single-precision floating-point number 2.0^x. * If the result is too small to be represented as a denorm, return * 0. If too large, return +INF. * * Legal ops: Any integer/unsigned operations incl. ||, &&. Also if, while * Max ops: 30 * Rating: 4 */ unsignedfloatPower2(int x){ intexp = x + 127; if (exp <= 0) return0; if (exp >= 255) return0xFF << 23; // 指数位均为1表示无穷大 returnexp << 23; // 把指数位放到正确的位置 }
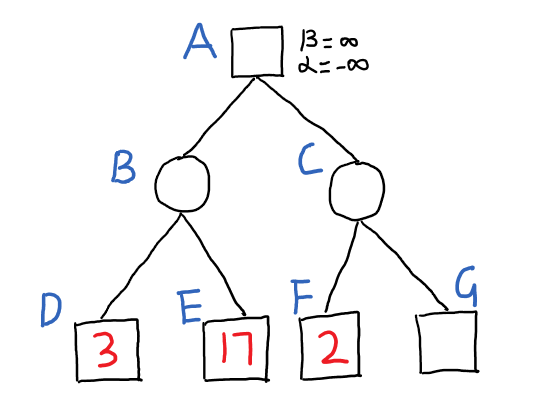
接下来我会尽量说明为什么剪枝这个操作是合理的,省略了一部分节点为什么不会对结果产生影响。用原图中以4号节点(第三层的第一个节点)为根节点的子树来举例,方便描述这里将他们用A - G 的字母来重新标记。
子树
从 B 节点看起,B 是 min 节点,需要在 D 和 E 中寻找较小值,因此 B取值为3,同时 B 的 beta 值也设置为 3。假设 B还有更多值大于3的子节点,但因为已经出现了 D 这个最小值,所以不会对 B产生影响,即这里的 beta = 3 确定了一个上界。
A 是 max 节点,需要在 B 和 C 中找到较大值,因为子树 B 已经搜索完毕,B的值确定为 3,所以 A 的值至少为 3,这样确定了 A 的下界 alpha = 3。在搜索C 子树之前,我们希望 C 的值大于3,这样才会对 A 的下界alpha 产生影响。于是 C 从 A 这里获得了下界 alpha = 3 这个限制条件。
C 是 min 节点,要从 F 和 G 里找出较小值。F 的值为2,所以 C的值一定小于等于 2,更新 C 的上界 beta = 2。此时 C 的 alpha = 3, beta =2,这是一个空区间,也就是说即使继续考虑 C 的其它子节点,也不可能让 C 的值大于 3,所以我们不必再考虑 G 节点。G节点就是被剪枝的节点。
重复这样的过程,会有更多的节点因为剪枝操作被忽略,从而对 minimax算法进行了优化。
Alpha-beta 剪枝算法的实现
接下来讨论如何修改前面实现的 minimax 算法,使其变为 alpha-beta剪枝算法。
第一步在 constructor 中加入两个新属性,alpha、beta。
1 2 3 4 5 6 7 8
constructor(data, type, depth, alpha, beta) { this.data = data; this.type = type; // 区分此节点的种类是 max 或 min this.depth = depth;
想看英语原版书来着,不过还没找到什么感兴趣的,于是又去看哈利波特了:- Holes - Hyperion (半本) - Harry Potter and the Sorcerer's Stone -Harry Potter and the Chamber of Secrets - Harry Potter and the Prisonerof Azkaban - Harry Potter and the Goblet of Fire (目前为止看了46%)
为了能够记录下图片的信息,需要记录每一个像素点的 RGB值,对于一张宽度为 W,高度为 H 的图片,其像素点数量为W * H,而每个像素点分别用三个数来表示其 R、G、B值,所以记录下整张图片的数据,需要一个长度为 W * H * 3的数组。如果图片带有 alpha 通道,需要记录 RGBA值,则数组长度为W * H * 4。这里有一个可以简化的地方,因为绘制的是一张黑白的图片,对于黑/白/灰色来说R = G = B,所以用长度 W * H 的数组即可。
const p = []; for (let y = 0, i = 0; y < HEIGHT; y++) { for (let x = 0; x < WIDTH; x++) { // x / W, y / H 其值被限制在 [0, 1] 之间 p[i++] = Math.floor(Math.min(sample(x / WIDTH, y / HEIGHT) * 255, 255)); } }
利用蒙特卡罗积分法进行 N 次采样取平均值获得 (x, y)处的光照强度,其中的 trace() 函数代表的是从 \(\theta\) 方向获取的光强。
1 2 3 4 5 6 7 8 9 10 11 12 13
functionsample(x, y) { let sum = 0; for (let i = 0; i < N; i++) { // 以下为三种不同的采样方式 // const theta = Math.PI * 2 * Math.random(); // 随机采样 // const theta = Math.PI * 2 * i / N; // 分层采样(stratified sampling) const theta = Math.PI * 2 * (i + Math.random()) / N; // 抖动采样(jittered sampling)
// trace() 所返回的值是点 (x, y) 从 theta 方向获取的光 sum += trace(x, y, Math.cos(theta), Math.sin(theta)); } return sum / N; }
]]>
<blockquote>
<p>Any application that <strong>can</strong> be written in JavaScript,
<strong>will</strong> eventually be written in JavaScript. -- Atwood's
Law</p>
</blockquote>
<p>本文来源于我在看了 Milo Yip 在知乎专栏里的这篇文章:<a
href="https://zhuanlan.zhihu.com/p/30745861">《用 C
语言画光(一):基础》</a>之后的一个想法,能不能将原文中 C
语言版本程序改成 JavaScript
版本的。动手之后发现出乎意料的顺利,我只需要把 C
语言中变量的类型通通去掉就可以了😀,Amazing!</p>
塔防游戏中的敌人如何沿路径前进 (JavaScript 实现)http://www.wukai.me/2017/12/09/boid-path-following/2017-12-08T16:00:00.000Z2021-12-21T13:55:03.545Z如果开发一个塔防游戏,很自然的会遇上这么两个名字很像的问题:
io.on('connection', function(socket){ socket.emit('request', /* */); // emit an event to the socket io.emit('broadcast', /* */); // emit an event to all connected sockets socket.on('reply', function(){ /* */ }); // listen to the event });
Note: Socket.IO is not a WebSocket implementation. Although Socket.IOindeed uses WebSocket as a transport when possible, it adds somemetadata to each packet: the packet type, the namespace and the ack idwhen a message acknowledgement is needed.
]]>
<p>写这篇博客的起因是我看了Medium上的这篇文章:<a
href="https://blog.prototypr.io/how-i-started-drawing-css-images-3fd878675c89">How
I started drawing CSS
Images</a>,然后哇哦😦,同样是前端开发,这区别怎么这么大呢?这位作者和我完全点了不同的技能点啊!</p>
<p>看了几个她在codepen上的作品,比如这个<a
href="http://codepen.io/sashatran/pen/VmwmJO">皮卡丘</a>,发现用到的技术也并不多,于是我也想试试。</p>
<p>不过有哪个动漫中的人物足够简单,能够用几个基本的几何图形就画出来呢?我想到了一个人,于是我决定画一个《一拳超人》中的<del>卤蛋</del>,不对,是<del>秃头披风侠</del>——琦玉老师。</p>
课程笔记--Building a javascript development environmenthttp://www.wukai.me/2017/03/05/lesson-note-build-a-javascript-development-environment/2017-03-04T16:00:00.000Z2021-12-21T13:55:03.545Z这篇博客是我在学习 Pluralsight上的课程:Buildinga JavaScript Development Environment时记下的笔记,仅作个人记录之用。


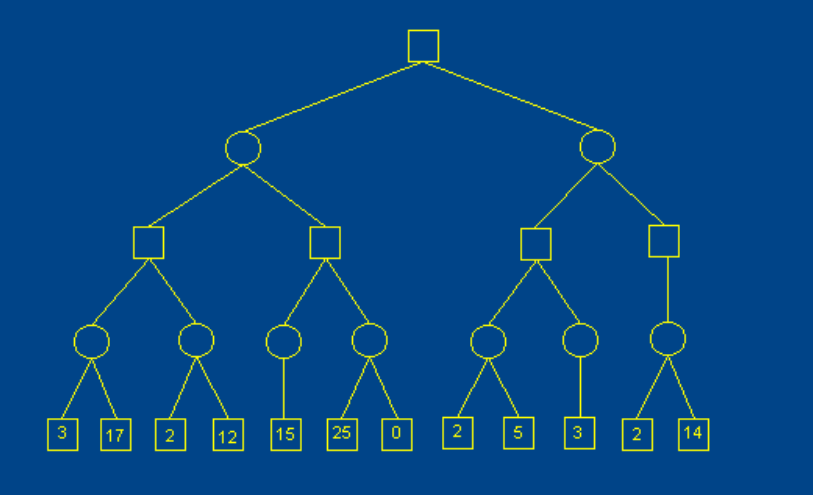 (图片来自于http://web.cs.ucla.edu/~rosen/161/notes/alphabeta.html)
(图片来自于http://web.cs.ucla.edu/~rosen/161/notes/alphabeta.html)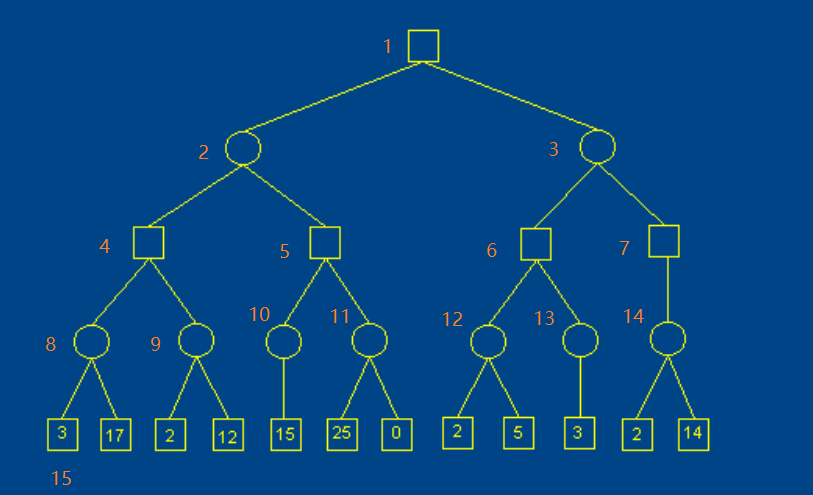
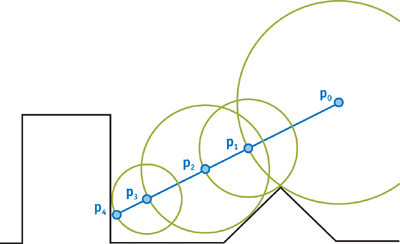 (图源:https://developer.nvidia.com/gpugems/GPUGems2/gpugems2_chapter08.html)
(图源:https://developer.nvidia.com/gpugems/GPUGems2/gpugems2_chapter08.html)